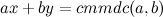Vectorii (tablourile de memorie) sunt structuri simple şi eficiente de memorare a obiectelor într-o anumită ordine, dar au şi dezavantaje. Nu sunt foarte adaptabili, de exemplu, inserarea şi ştergerea elementelor sunt dificile deoarece elementele trebuie să fie deplasate pentru a face loc inserţiei sau pentru a umple poziţiile rămase libere după ştergere. De aceea avem nevoie de o alternativă la vectori care să implementeze o secvenţă de elemente. În acest tutorial voi prezenta lista liniară simplu înlănţuită.
O listă simplu înlănţuită este o colecţie de noduri aşezate într-o ordine liniară (dar NU în locaţii succesive din memorie - aşa cum se întâmplă la vectori). Fiecare nod are cel puţin un pointer către următorul nod, pe care îl voi numi next (în imagine este urm). Primul nod se numeşte head (sau prim), iar ultimul nod se numeşte tail (sau ultim), dar bineînţeles că nu există o regulă strictă cu privire la aceste nume (puteţi să le numiţi cum vreţi). Lista se numeşte simplu înlănţuită deoarece fiecare nod memorează un singur pointer către următorul nod. Spre deosebire de vectori, lista nu are o mărime fixă. Poate fi redimensionată prin adăugarea sau ştergerea nodurilor. Gândiţi-vă la un nod ca la un obiect (item) care conţine atât informaţia pe care vreţi s-o stocaţi cât şi legătura către următorul obiect. Pentru a semnala sfârşitul listei folosim NULL. Pointerului next al ultimului nod (nodul terminal) îi atribuim adresa NULL (Pentru cei care folosiţi compilatoare noi, cum ar fi cel din Visual Studio, folosiţi nullptr în loc de NULL, deoarece NULL este doar un simplu macro, este 0, este un întreg şi nu reprezintă concret o adresă inexistentă). Mai jos este o imagine ce ilustrează conceptul de listă simplu înlănţuită (LSÎ):
În tutorialele ce urmează voi folosi programarea obiect-orientată, deci ar fi bine să vă familiarizaţi cu această paradigmă. Totuşi, dacă sunteţi aici doar pentru algoritmii listei, atunci nu este necesar să cunoaşteţi POO (deşi ar fi bine). De asemenea, folosesc Visual Studio 12.
Implementarea Listei Simplu Înlănţuite
Voi defini o clasă numită
Lista, ce implementează LSÎ. Fiecare
nod va memora două valori, membrul
data care stochează informaţia propriu-zisă (în acest caz va fi un întreg) şi membrul
next care este un pointer către următorul nod al listei (
legătura).
class Lista
{
public:
struct Iterator; // Declaratie forward
Lista(); // Constructor - Initializarea listei
~Lista(); // Destructor - Distrugerea listei
void push_front(int elem); // Inserare in fata primului nod
void push_back(int elem); // Inserare dupa ultimul nod
void insert_before(int elem, Iterator nod); // Inserare inainte de nod
void insert_after(int elem, Iterator nod); // Inserare dupa nod
Iterator search(int value) const; // Lista contine value?
void pop_front(); // Elimina nodul din fata
void pop_back(); // Elimina ultimul nod
void remove(Iterator nod); // Elimina nodul nod
Iterator front() const; // Returneaza un iterator catre inceputul listei
Iterator end() const; // Returneaza un iterator catre sfarsitul listei
bool isEmpty() const; // Este lista vida?
void clear(); // Stergerea completa a listei
private:
struct Nod // Clasa Helper; Implementeaza un nod de lista
{
int data; // informatia propriu-zisa
Nod * next; // urm
};
Nod * head; // prim
Nod * tail; // ultim
public:
struct Iterator // Un pointer inteligent
{
friend class Lista; // Lista are acces la membrii privati ai lui Iterator
Iterator() { list = nullptr; }
Iterator(Nod * ls) { list = ls; }
// Supraincarc operatorul * (dereferentiere)
int& operator*() { if(list != nullptr) return list->data; else throw "Null iterator!"; }
// Prefix - Trec la urmatorul nod
Iterator& operator++() { list = list->next; return *this; }
// Postfix
Iterator operator++(int) { Iterator temp = *this; ++(*this); return temp; }
bool operator==(const Iterator& it) const { if(it.list == this->list) return true; else return false; }
bool operator!=(const Iterator& it) const { if(!(it == *this)) return true; else return false; }
private:
Nod * list;
};
};
Clasa
Nod şi cei doi pointeri sunt privaţi deoarece nu vreau ca utilizatorul clasei să aibă acces direct la ei; nu vreau să fie alteraţi de codul client. De asemenea declar clasa
Iterator, pentru a putea parcurge lista (
Iterator este membru static public al clasei
Lista). De ce fac asta? Deoarece
Nod este privat, nu pot folosi un pointer simplu către
Lista deoarece ar trebui ca
Nod să fie public în acel caz, ori eu nu vreau asta, vreau să respect principiul încapsulării şi să protejez datele interne ale clasei. Dacă
Nod ar fi public există riscul ca cel care foloseşte clasa mea să modifice (poate face asta fără să vrea, din greşeală, sau intenţionat) adresa către care pointează
next (membrul lui
Nod), iar în acest caz lista nu ar mai fi listă, deoarece ar exista o
ruptură. Aceeaşi explicaţie pentru
head şi
tail (aceste detalii ţin de POO, nicidecum de LSÎ, deci pot fi ignorate). Din această cauză implementez clasa
Iterator. Dacă tot nu înţelegeţi de ce am declarat această clasă, mai aşteptaţi puţin şi veţi înţelege. Ok, acum să trecem la lista simplu înlănţuită.
Lista vidă
Dacă lista este vidă înseamnă că atât
head cât şi
tail au valoarea
NULL (nullptr). Deci trebuie să testez dacă
head este
NULL. Funcţia
isEmpty() returnează
true dacă lista este vidă şi
false dacă nu este.
bool Lista::isEmpty() const
{
// Se evalueaza expresia si se returneaza rezultatul
return head == nullptr;
}
Iniţializarea listei
Voi iniţializa lista în constructorul clasei
Lista. Iniţializarea presupune crearea listei vide;
head şi
tail au valoarea
NULL.
Lista::Lista()
{
// Se creeaza lista vida
head = tail = nullptr;
}
Adăugarea unui nod la listă
Avem 3 cazuri:
- Inserarea în faţa primului nod;
- Inserarea după ultimul nod;
- Inserarea în interiorul listei.
Inserarea în faţa primului nod [push_front()]. Aici avem două cazuri: dacă lista este vidă atunci adăugăm atât la
head cât şi la
tail primul nod (iar pointerul
next va fi
NULL deoarece este singurul nod din listă), altfel adăugăm nodul în faţa listei. Aloc memorie pentru noul nod (să zicem
p) -> Scriu informaţia în
p -> Leg nodul
p de nodul
head ->
p devine noul
head (adică
head indică adresa lui
p).
void Lista::push_front(int elem)
{
// Daca lista este vida, atunci
if(isEmpty())
{
head = new Nod; // Aloc memorie pentru primul nod
head->data = elem;
head->next = nullptr; // Fiind singurul nod, urmatorul este NIMIC adica NULL
tail = head; // si tail == head
}
else // altfel
{
Nod * nod = new Nod; // Aloc memorie pentru noul nod
nod->data = elem; // Scriu informatia in data
nod->next = head; // Leg nod de head
head = nod; // nod devine noul head
}
}
Inserarea după ultimul nod [push_back()]. Şi aici avem cele două cazuri. Dacă lista nu este vidă, adăugăm nodul la sfârşitul listei. Se alocă memorie pentru noul nod p -> Scriu informaţia în nod -> Leg ultimul nod de nodul p -> p devine noul tail (adică p se leagă de NULL şi tail indică acum nodul p).
void Lista::push_back(int elem)
{
// Daca lista este vida, atunci
if(isEmpty())
{
head = new Nod; // Aloc memorie pentru primul nod
head->data = elem;
head->next = nullptr; // Fiind singurul nod, urmatorul este NIMIC adica NULL
tail = head; // si tail == head
}
else // altfel
{
Nod * nod = new Nod; // Aloc memorie pentru noul nod
nod->data = elem; // Scriu informatia in data
nod->next = nullptr; // Devenind nod terminal, va fi legat de NULL
tail->next = nod; // Fostul tail este legat de noul tail
tail = nod; // nod devine tail
}
}
Inserarea în interiorul listei.
Inserarea după nodul q (unde q este un nod al listei pe care îl obţineţi iterând prin listă). Se alocă memorie pentru noul nod (newNod) -> Leg nodul newNod de succesorul nodului q -> Nodul q se leagă de nodul newNod. Dacă q a fost nod terminal, atunci newNod este acum nod terminal.
void Lista::insert_after(int elem, Iterator nod)
{
Nod * newNod = new Nod; // Aloc memorie pentru noul nod
newNod->data = elem; // Scriu informatia in data
newNod->next = nod.list->next; // newNod se leaga de succesorul lui 'nod'
nod.list->next = newNod; // Nodul 'nod' se leaga de newNod
// Daca nodul 'nod' a fost ultimul nod, atunci nodul newNod devine nod terminal
if(newNod->next == nullptr) tail = newNod;
}
Chiar dacă am spus nodul nod, nod nu este de fapt Nod, este un obiect Iterator. Prin nodul nod mă refer la nodul încapsulat în obiectul Iterator nod (adică membrul list).
Inserarea înainte de nodul q. Pentru a adăuga nodul newNod înainte de nodul p, ar trebui să leg predecesorul nodului q de newNod, dar eu nu cunosc acest predecesor. În acest caz voi insera nodul newNod după nodul p şi voi interschimba informaţia din cele două noduri dând impresia unei inserări înainte. Algoritmul este acelaşi, dar cu mici modificări.
void Lista::insert_before(int elem, Iterator nod)
{
Nod * newNod = new Nod; // Aloc memorie pentru noul nod
// --- Interschimb informatia --- //
newNod->data = nod.list->data; // Copiez informatia din 'nod' in newNod
nod.list->data = elem; // 'nod' va memora informatia care trebuie adaugata la lista
// ------------------------------ //
newNod->next = nod.list->next; // newNod se leaga de succesorul lui 'nod'
nod.list->next = newNod; // Nodul 'nod' se leaga de newNod
// Daca nodul 'nod' a fost ultimul nod, atunci nodul newNod devine nod terminal
if(nod.list == tail) tail = newNod;
}
Inserţia (cei patru algoritmi) în listă se realizează în timp constant \(O(1)\).
Parcurgerea listei
Lista se parcurge folosind un
Iterator. Algoritmul de parcurgere l-am implementat deja în funcţia
operator++() (ambele) a clasei
Iterator. Ideea este următoarea: Se obţine un pointer (în cazul meu un
Iterator) către primul nod (
head), apoi se parcurge lista actualizând pointerul (iteratorul) curent cu următorul element (
nod = nod->next) până când pointerul curent indică
NULL (în cazul meu iteratorul ajunge la
end()), adică pointerul curent indică nodul imediat următor după
tail.
Iterator& operator++() { list = list->next; return *this; }
Împreună cu funcţiile
front() şi
end() putem parcurge lista. Cele două funcţii sunt definite în felul următor:
Lista::Iterator Lista::front() const { return Iterator(head); }
Lista::Iterator Lista::end() const { return Iterator(nullptr); }
Observaţi că funcţia
end() returnează un
Iterator ce încapsulează un
Nod NULL. Acesta este nodul imediat următor după nodul
tail al listei. Deci de fiecare dată când prelucrez lista, voi prelucra informaţiile din intervalul \([front, end)\). Iată algoritmul general de parcurgere a listei:
Lista myList; // declar o lista
for(Lista::Iterator iter = myList.front(); iter != myList.end(); iter++)
{
// Se prelucreaza (*iter)
}
Căutarea unui nod în listă
Căutarea este destul de simplă. Pur şi simplu parcurgem lista şi verificăm dacă valoarea care ne interesează se află în nodul curent. Dacă o găsim, returnăm un iterator către acest nod. Căutarea o voi implementa în funcţia
search().
Lista::Iterator Lista::search(int value) const
{
for(Nod* it = head; it != nullptr; it = it->next)
{
if(it->data == value) return Iterator(it); // Daca am gasit nodul il returnez
}
return end(); // Nu am gasit nimic
}
Algoritmul de căutare este liniar $O(n)$
Eliminarea unui nod din listă
Avem 3 cazuri:
- Eliminarea primului nod;
- Eliminarea ultimuluiu nod;
- Eliminarea unui nod din interiorul listei.
Eliminarea primului nod [pop_front()]. Sunt câteva cazuri care trebuie luate în considerare: lista este vidă sau lista are un singur nod.
Oricum ar fi, algoritmul general este următorul: Salvez nodul
head într-un nod oarecare
temp -> Succesorul nodului
head devine nod
head -> Se eliberează memoria ocupată de obiectul referit de nodul
temp (fostul
head).
void Lista::pop_front()
{
if(isEmpty()) throw "Empty List"; // Daca lista este vida
if(head == tail) // Daca lista are un singur nod
{ delete head; head = tail = nullptr; return; }
Nod * temp = head; // Salvez adresa obiectului head
head = head->next; // Succesorul lui head devine noul head
delete temp; // Eliberez memoria ocupata de vechiul obiect head
}
Algoritmul de eliminare a primului nod este constant $O(1)$.
Eliminarea ultimului nod [pop_back()]
Caut predecesorul nodului
tail prin parcurgerea listei -> Predecesorul nodului
tail devine nod terminal -> Eliberez zona de memorie ocupată de fostul
tail -> Predecesorul devine nod
tail.
void Lista::pop_back()
{
if(isEmpty()) throw "Empty List"; // Daca lista este vida
if(head == tail) // Daca lista are un singur nod
{ delete head; head = tail = nullptr; return; }
// Caut predecesorul lui tail
Nod * pred;
for(pred = head; pred->next->next != nullptr; pred = pred->next); // For Vid
pred->next = nullptr; // Predecesorul devine nod terminal
delete tail; // Eliberez memoria ocupata de vechiul obiect tail
tail = pred; // Predecesorul devine tail
}
Algoritmul de eliminare a ultimului nod este liniar $O(n)$.
Eliminarea unui nod din interiorul listei
Deoarece nu cunosc predecesorul unui nod, eliminarea unui nod înseamnă de fapt eliminarea informaţiei acelui nod. Aşadar, din listă nu va fi eliminat nodul
nod ci succesorul său (care este cunoscut), asta după ce informaţia din succesor este salvată în
nod. Dacă succesorul nodului
nod era nodul
tail, atunci nodul
nod devine nod
tail. Algoritmul este implementat în funcţia
remove() care ia ca parametru un obiect de tip
Iterator.
void Lista::remove(Iterator nod)
{
if(isEmpty()) throw "Empty List"; // Daca lista este vida
if(head == tail) // Daca lista are un singur nod
{ delete head; head = tail = nullptr; return; }
Nod * temp = nod.list->next; // Salvez adresa succesorului lui 'nod'
// Copiez toata informatia succesorului in 'nod'
nod.list->data = nod.list->next->data;
nod.list->next = nod.list->next->next;
delete temp; // Eliberez memoria ocupata de succesor; il elimin
if(nod.list->next == nullptr) tail = nod.list;
}
Algoritmul de eliminare al unui nod din interiorul listei este constant \(O(1)\).
Ştergerea listei
Algoritmul pentru eliberarea spaţiului de memorie ocupat de listă (ştergerea listei) este următorul:
void Lista::clear()
{
Nod *it = head, *temp;
while(it != nullptr)
{
temp = it; // Salvez adresa nodului curent
it = it->next; // Trec mai departe
delete temp; // Distrug nodul curent
}
head = tail = nullptr; // Lista Vida
}
Algoritmul de ştergere a listei este liniar \(O(n)\). Şi să nu uităm de destructorul clasei:
Lista::~Lista()
{ if(!isEmpty()) clear(); }
În continuare vă propun să creaţi un nou fişier
Liste.h (
header) şi să-l adăugaţi la proiectul vostru, după care în fişierul
main (unde aveţi funcţia
main) să adăugaţi, la început, directiva:
#include "Liste.h". Adăugaţi următorul cod în
Liste.h:
class Lista
{
public:
struct Iterator; // Declaratie forward
// Constructor - Initializarea listei
Lista() { head = tail = nullptr; /*Se creeaza lista vida*/ }
// Destructor - Distrugerea listei
~Lista() { if(!isEmpty()) clear(); }
void push_front(int elem); // Inserare in fata primului nod
void push_back(int elem); // Inserare dupa ultimul nod
void insert_before(int elem, Iterator nod); // Inserare inainte de nod
void insert_after(int elem, Iterator nod); // Inserare dupa nod
Iterator search(int value) const; // Cauta value in lista
void pop_front(); // Elimina nodul din fata
void pop_back(); // Elimina ultimul nod
void remove(Iterator nod); // Elimina nodul nod
// Returneaza un iterator catre inceputul listei
Iterator front() const { return Iterator(head); }
// Returneaza un iterator catre sfarsitul listei
Iterator end() const { return Iterator(nullptr); }
bool isEmpty() const { return head == nullptr; } // Este lista vida?
void clear(); // Stergerea completa a listei
private:
struct Nod // Clasa Helper; Implementeaza un nod de lista
{
int data; // informatia propriu-zisa
Nod * next; // urm
};
Nod * head; // prim
Nod * tail; // ultim
public:
struct Iterator // Un pointer inteligent
{
friend class Lista; // Lista are acces la membrii privati ai lui Iterator
Iterator() { list = nullptr; }
Iterator(Nod * ls) { list = ls; }
// Supraincarc operatorul * (dereferentiere)
int& operator*() { if(list != nullptr) return list->data; else throw "Null iterator!"; }
// Prefix - Trec la urmatorul nod
Iterator& operator++() { list = list->next; return *this; }
// Postfix
Iterator operator++(int) { Iterator temp = *this; ++(*this); return temp; }
bool operator==(const Iterator& it) const { if(it.list == this->list) return true; else return false; }
bool operator!=(const Iterator& it) const { if(!(it == *this)) return true; else return false; }
private:
Nod * list;
};
};
void Lista::push_front(int elem)
{
// Daca lista este vida, atunci
if(isEmpty())
{
head = new Nod; // Aloc memorie pentru primul nod
head->data = elem;
head->next = nullptr; // Fiind singurul nod, urmatorul este NIMIC adica NULL
tail = head; // si tail == head
}
else // altfel
{
Nod * nod = new Nod; // Aloc memorie pentru noul nod
nod->data = elem; // Scriu informatia in data
nod->next = head; // Leg nod de head
head = nod; // nod devine noul head
}
}
void Lista::push_back(int elem)
{
// Daca lista este vida, atunci
if(isEmpty())
{
head = new Nod; // Aloc memorie pentru primul nod
head->data = elem;
head->next = nullptr; // Fiind singurul nod, urmatorul este NIMIC adica NULL
tail = head; // si tail == head
}
else // altfel
{
Nod * nod = new Nod; // Aloc memorie pentru noul nod
nod->data = elem; // Scriu informatia in data
nod->next = nullptr; // Devenind nod terminal, va fi legat de NULL
tail->next = nod; // Fostul tail este legat de noul tail
tail = nod; // nod devine tail
}
}
void Lista::insert_after(int elem, Iterator nod)
{
Nod * newNod = new Nod; // Aloc memorie pentru noul nod
newNod->data = elem; // Scriu informatia in data
newNod->next = nod.list->next; // newNod se leaga de succesorul lui 'nod'
nod.list->next = newNod; // Nodul 'nod' se leaga de newNod
// Daca nodul 'nod' a fost ultimul nod, atunci nodul newNod devine nod terminal
if(nod.list == tail) tail = newNod;
}
void Lista::insert_before(int elem, Iterator nod)
{
Nod * newNod = new Nod; // Aloc memorie pentru noul nod
// --- Interschimb informatia --- //
newNod->data = nod.list->data; // Copiez informatia din 'nod' in newNod
nod.list->data = elem; // 'nod' va memora informatia care trebuie adaugata la lista
// ------------------------------ //
newNod->next = nod.list->next; // newNod se leaga de succesorul lui 'nod'
nod.list->next = newNod; // Nodul 'nod' se leaga de newNod
// Daca nodul 'nod' a fost ultimul nod, atunci nodul newNod devine nod terminal
if(nod.list == tail) tail = newNod;
}
Lista::Iterator Lista::search(int value) const
{
for(Nod* it = head; it != nullptr; it = it->next)
{
if(it->data == value) return Iterator(it); // Daca am gasit nodul il returnez
}
return end(); // Nu am gasit nimic
}
void Lista::pop_front()
{
if(isEmpty()) throw "Empty List"; // Daca lista este vida
if(head == tail) // Daca lista are un singur nod
{ delete head; head = tail = nullptr; return; }
Nod * temp = head; // Salvez adresa obiectului head
head = head->next; // Succesorul lui head devine noul head
delete temp; // Eliberez memoria ocupata de vechiul obiect head
}
void Lista::remove(Iterator nod)
{
if(isEmpty()) throw "Empty List"; // Daca lista este vida
if(head == tail) // Daca lista are un singur nod
{ delete head; head = tail = nullptr; return; }
Nod * temp = nod.list->next; // Salvez adresa succesorului lui 'nod'
// Copiez toata informatia succesorului in 'nod'
nod.list->data = nod.list->next->data;
nod.list->next = nod.list->next->next;
delete temp; // Eliberez memoria ocupata de succesor; il elimin
if(nod.list->next == nullptr) tail = nod.list;
}
void Lista::pop_back()
{
if(isEmpty()) throw "Empty List"; // Daca lista este vida
if(head == tail) // Daca lista are un singur nod
{ delete head; head = tail = nullptr; return; }
// Caut predecesorul lui tail
Nod * pred;
for(pred = head; pred->next->next != nullptr; pred = pred->next); // For Vid
pred->next = nullptr; // Predecesorul devine nod terminal
delete tail; // Eliberez memoria ocupata de vechiul obiect tail
tail = pred; // Predecesorul devine tail
}
void Lista::clear()
{
Nod *it = head, *temp;
while(it != nullptr)
{
temp = it; // Salvez adresa nodului curent
it = it->next; // Trec mai departe
delete temp; // Distrug nodul curent
}
head = tail = nullptr; // Lista Vida
}
În final, iată un exemplu cu liste:
#include <iostream>
#include "Liste.h"
using namespace std;
int main()
{
Lista myList; // Declar o lista
myList.push_back(4);
myList.push_back(3);
myList.push_front(7);
for(Lista::Iterator it = myList.front(); it != myList.end(); it++)
cout << *it << ' ';
cout << '\n';
Lista::Iterator p = myList.search(4);
myList.insert_after(5, p);
myList.insert_before(2, p);
for(Lista::Iterator it = myList.front(); it != myList.end(); it++)
cout << *it << ' ';
cout << '\n';
myList.pop_back();
myList.pop_front();
p = myList.search(4);
myList.remove(p);
for(Lista::Iterator it = myList.front(); it != myList.end(); it++)
cout << *it << ' ';
cout << '\n';
myList.clear();
if(myList.isEmpty()) cout << "Lista vida!\n";
system("PAUSE");
return 0;
}
Output:
7 4 3
7 2 4 5 3
2 5
Lista vida!
Dacă aveţi probleme cu
nullptr, atunci folosiţi
NULL. De asemenea vă recomand să folosiţi
Visual Studio.